Íslensk orðtíðnibók var gefin út 1991. Þar eru birtar niðurstöður viðamikilla rannsókna á íslensku nútímamáli sem beindust að tíðni orða og málfræðiatriða í textum af ýmsu tagi. Í formála er gerð rækileg grein fyrir verkinu í heild, bæði rannsóknunum og bókinni sjálfri. Niðurstöðurnar er síðan að finna í fjórtán meginköflum þar sem tíðni orða og málfræðiatriða er birt í skrám og töflum. Ritstjóri bókarinnar var Jörgen Pind en samstarfsmenn hans voru Friðrik Magnússon og Stefán Briem. Búið var til sérstakt textasafn fyrir gerð bókarinnar. Textasafninu eru gerð skil á þessari vefsíðu og veittur er aðgangur að því. Leita má í textunum og einnig er unnt að sækja textana og nota þá við málrannsóknir og í máltækniverkefnum.
Fyrir vinnslu Íslenskrar orðtíðnibókar (Jörgen Pind, Stefán Briem og Friðrik Magnússon 1991) sem Orðabók Háskólans gaf út 1991 var gert sérstakt textasafn. Vinna við undirbúning textasafnsins hófst 1985 og er safninu lýst nákvæmlega í formála Orðtíðnibókarinnar. Í textasafninu eru brot úr 100 textum sem voru gefnir út á tímabilinu 1980-1989, hvert með um 5.000 lesmálsorðum. Textarnir voru valdir úr fimm textaflokkum: íslenskum skáldverkum (20 textar), þýddum skáldverkum (20 textar), ævisögum og minningum (20 textar), fræðslutextum (10 á sviði hugvísinda, 10 á sviði raunvísinda) og barna og unglingabókum (10 frumsamdir textar, 10 þýddir textar).
Í formála Orðtíðnibókarinnar er lesmálsorð skilgreint sem samfelld röð af bókstöfum og/eða tölustöfum og táknum sem aðgreind eru með stafbili eða greinarmerkjum. Notuð var sú regla að reynt var að fella eins langan stafastreng undir töluorð og kostur var. Plúsar, mínusar og prósentumerki fylgdu þannig lesmálsorðunum. Blendingar tölustafa og annarra rittákna, t.d. efnafræðiformúlur og stærðfræðiformúlur teljast eitt lesmálsorð. Vert er að benda á að skammstafanir eru í flestum tilvikum greindar eins og lesið er úr þeim.
Textunum var skipt í lesmálsorð og í textasafninu eru 590.297 lesmálsorð sem birtast í 59.358 mismunandi orðmyndum að meðtöldum greinarmerkjum. Lesmálsorðunum fylgja 639 mismunandi greiningarstrengir að meðtöldum greinarmerkjum. Þegar fengist er við vélræna málfræðilega greiningu er erfiðast að eiga við orðmyndir sem geta haft fleiri en eina greiningu. Í textasafni Orðtíðnibókarinnar hafa 15,9% orðmynda fleiri en eina hugsanlega greiningu. Margræðasta orðmyndin er minni sem hefur 24 greiningarstrengi í textasafninu, en fleiri eru mögulegir (ég minni þig á það; ég geri þetta eftir minni; Nonni er minni en Siggi; o.s.frv.)
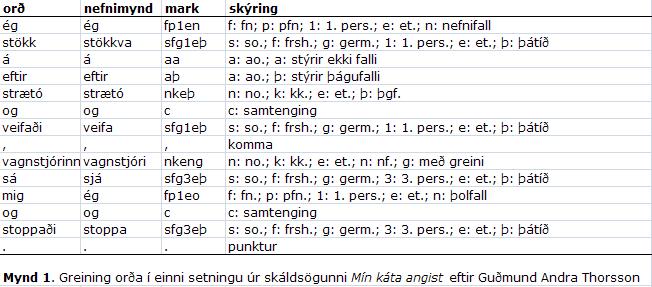
Hverju lesmálsorði var síðan komið fyrir í sérstakri línu. Í þeirri línu var einnig komið fyrir greiningarstreng orðsins eða marki og nefnimynd (flettimynd) þess. Í myndinni hér að neðan er sýnd ein setning úr skáldsögunni Mín káta angist eftir Guðmund Andra Thorsson og hvernig hún er greind. Til glöggvunar er sýnd skýring á greiningarstrengjum.
Í formála Orðtíðnibókarinnar er gerð grein fyrir vélrænni greiningu sem notuð var við gerð bókarinnar (Jörgen Pind, Friðrik Magnússon og Stefán Briem 1991). Vélræna greiningin byggist á greiningu 54.000 lesmálsorða sem höfðu verið greind handvirkt og notuð við orðtíðnikönnun (Friðrik Magnússon, 1988). Stefán Briem (1990) gerir grein fyrir aðferðum sem var beitt við vélrænu greininguna. Höfundar Orðtíðnibókarinnar telja að um 80% lesmálsorða hafi fengið rétta greiningu að öllu leyti með vélrænu greiningunni. Nokkrum árum seinna var forritið endurbætt á grundvelli greiningar alls textans. Fékkst þá tæplega 90% nákvæmni (Stefán Briem, munnlegar upplýsingar).
Í greiningu lesmálsorða sem notuð var í Orðtíðnibókinni er greint á milli átta orðflokka: nafnorða, lýsingarorða, fornafna, lauss greinis, töluorða, sagna, atviksorða og samtenginga. Orð sem ekki flokkast í þessa orðflokka voru annað hvort talin erlend orð eða ógreind orð. Helstu frávik frá venjulegri orðflokkagreiningu voru þau að forsetningar voru taldar með atviksorðum. Þess vegna koma fyrir atviksorð sem stýra falli. Upphrópanir voru einnig taldar með atviksorðum. Nafnháttarmerki var talið með samtengingum.
Í formála bókarinnar er tafla sem lýsir markaskrá Orðtiðnibókarinnar. Greiningarstrengir eru runa bókstafa sem hver um sig lýsir tilteknu málfræðiatriði. Í töflunni eru skýringar skammstafana í greiningarstrengjum og þar er röð atriða sú sama og er birt í töflum í bókinni. Í tölvutækum aðgangi að efni Orðtíðnibókarinnar er form greiningarstrengja það sama og í þeim skrám sem notaðar voru við vinnslu bókarinnar. Þar eru notaðir lágstafir til þess að tákna málfræðiatriði og röð bókstafa í greiningarstrengjunum er önnur en kemur fram í prentaðri bók. Í tölvutækum skrám Orðtíðnibókarinnar koma fyrir 639 greiningarstrengir að meðtöldum greinarmerkjum. Hugsanlegir greiningarstrengir í markaskránni sem fylgir tölvutækum skrám eru hins vegar um 700.
Allir textar sem voru notaðir við gerð Orðtíðnibókarinnar eru varðir af höfundarrétti. Efnið er gert aðgengilegt á þrenns konar hátt. Í fyrsta lagi er veittur leitaraðgangur þar sem aðeins má sjá allt að 500 bókstafi í einu (5-6 línur) og er þessi aðgangur innan ramma höfundalaga (nr. 73/1972). Í öðru lagi geta notendur fengið afrit af sömu textum til málfræðilegra rannsókna og fyrir máltækniverkefni gegn því að samþykkja sérstakt notkunarleyfi. Í þriðja lagi eru textarnir aðgengilegir fyrir þjálfun tölfræðilegra markara en þá er búið að brjóta textana upp og raða þeim þannig saman að þeir eru óþekkjanlegir. Sjá nánar hér fyrir neðan.
Þó að mörk í textum Orðtíðnibókarinnar hafi verið leiðrétt handvirkt er óhjákvæmilegt að einhverjar villur hafi slæðst inn. Hrafn Loftsson gerði tilraun til þess að finna vélrænt og leiðrétta síðan villur í mörkum í Orðtíðnibókinni (Hrafn Loftsson, 2009). Þeir textar sem eru aðgengilegir í gegnum þessa vefsíðu eru með leiðréttum mörkum Hrafns. Þetta á við um leitaraðgang, xml-skjöl og skrár fyrir þjálfun markara.
Gerðar hafa verið tilraunir til þess að einfalda mörk í textum Orðtíðnibókarinnar (Hrafn Loftsson o. fl., 2011). Notendur fá hér einnig aðgang að textum með einni gerð af einfölduðum mörkum. Þessi einföldun felst í því að sérnöfn eru ekki sundurgreind (mannanöfn, örnefni og önnur sérnöfn eru öll mörkuð sem „önnur sérnöfn“ og fá markið n----s) og töluorð rituð með tölustöfum fá öll markið ta, þ.e. eru ekki mörkuð sem frumtölur sem beygjast. Þannig má sækja tvenns konar gagnapakka með textum í xml-sniði og tvenns konar pör til þess að þjálfa og prófa tiltekna mörkunaraðferð.
Lesa formála Orðtíðnibókarinnar í heild sinni.
(Ath. blaðsíðuskipting í þessu pdf skjali er ekki alveg sú sama og í prentuðu bókinni þannig að ef einhver ætlar að vísa í þennan formála sem heimild þarf að koma skýrt fram að um vefútgáfuna er að ræða.)
Markaskrá fyrir tölvutækar skrár Orðtíðnibókarinnar í pdf-sniði
Listi yfir texta sem má leita í og sækja.

Textar orðtíðnibókarinnar eru aðgengilegir til notkunar á þrenns konar vegu:
1. Leita í textunum. Leitin er aðgengileg á málheildarsíðu Stofnunar Árna Magnússonar. Nýta má málfræðilegar upplýsingar til þess að skilgreina leitina og jafnframt fást bókfræðilegar upplýsingar um textana sem leitarniðurstöður eru úr. Listi yfir verk sem unnt er að leita í er hér.
2. Sækja textana. Textarnir eru einnig aðgengilegir á varðveislusvæði CLARIN-IS í sérstöku xml-sniði sem er skilgreint af TEI (Text Encoding Initiative). Bókfræðilegar upplýsingar fylgja öllum textum.
3. Þjálfun markara. Til þess að þjálfa og prófa tiltekna mörkunaraðferð er oft notuð aðferð sem byggist á því að hafa til umráða tíu pör af þjálfunar- og prófunarsöfnum. Í hverri tölvuskrá Orðtíðnibókarinnar er 5000 orða textabútur úr einni heimild. Pörin voru búin til þannig að hverri skrá var skipt upp í tíu nokkurn veginn jafna hluta. Hver þessara tíu hluta myndar eitt prófunarsafn og samstætt þjálfunarsafn hefur að geyma hina hlutana níu í hvert sinn. Stærri skráin er notuð sem þjálfunarsafn og sú minni sem prófunarsafn. Prófunarsöfnin skarast því ekki en þjálfunarsöfnin hafa um 80% sameiginlega texta. Markarinn er þjálfaður og prófaður á öllum 10 pörum og fundin meðalnákvæmni (þessi aðferð er kölluð á ensku ten-fold cross-validation).
1Þegar birtar eru niðurstöður sem eru fengnar með því að nota gögn Orðtíðnibókarinnar vinsamlegast vitnið í: Jörgen Pind (ritstj.), Friðrik Magnússon og Stefán Briem. 1991. Íslensk orðtíðnibók. Orðabók Háskólans, Reykjavík. Aðgengilegt til leitar á malheildir.arnastofnun.is/mim.