The Icelandic Frequency Dictionary (IFD) was published in 1991. It presents the results of extensive research on Modern Icelandic which targeted the frequency of words and grammatical features of texts of various kinds. The Preface of the IFD gives a detailed account of the work as a whole, both the research and the book itself. The results can then be found in the fourteen chapters of the book, where the frequency of words and grammatical features are displayed in lists and tables. Jörgen Pind edited the book with collaborators Friðrik Magnússon and Stefán Briem. A special text corpus was created for the making of the book. This website contains a description of the corpus and makes it accessible online. The texts can be searched, but they can also be downloaded and used for linguistic research and language technology projects.
When publishing results based on the texts in the corpus of the IFD please refer to: J. Pind, F. Magnússon, and S. Briem. 1991. Íslensk orðtíðnibók [The Icelandic Frequency Dictionary]. The Institute of Lexicography, University of Iceland, Reykjavik, Iceland. Available online at malheildir.arnastofnun.is/otb.
A special text corpus was created for the making of the Icelandic Frequency Dictionary (Pind, Magnússon and Briem, 1991), published by The Institute of Lexicography in 1991. Preparations for the corpus started in 1985 and a detailed description of the work can be found in the preface to the book. There are fragments from 100 texts in the corpus, all published between the years 1980 and 1989. Each text contains about 5,000 running words. The texts were selected from five categories: Icelandic fiction (20 texts), translated fiction (20 texts), biographies and memoirs (20 texts), non-fiction (10 in the field of humanities, 10 in the field of science) and books for children and teenagers (10 original texts, 10 translations).
In the preface of the IFD, 'a running word' is defined as a continuous sequence of letters and/or numbers and symbols that are separated by a space or punctuation. The rule is to incorporate as long strings of characters as possible under each numeral. Plus signs, minus signs and percentage symbols, therefore, belong to a running word. Hybrids of numbers and other characters, such as chemical formulae and mathematical formulae are considered one running word. It should be noted that abbreviations are in most cases analyzed as they are read.
The texts were divided into running words, yielding 590,279 running words in the corpus that appear in 59,358 different word forms, including punctuation. The running words are followed by 639 morphosyntactic tags, including punctuation. In automatic grammatical analysis the most difficult part is to deal with word forms that can have more than one analysis. In the text corpus of IFD, 15.9% of the word forms are ambiguous as to tagsets within the IFD. The most ambiguous of the wordforms in the IFD is 'minni' with 24 morphosyntactic tags in the corpus, but others are possible (ég minni þig á það 'I remind you of that'; ég geri þetta eftir minni 'I do this from memory'; Nonni er minni en Siggi 'Nonni is smaller than Siggi', etc.).
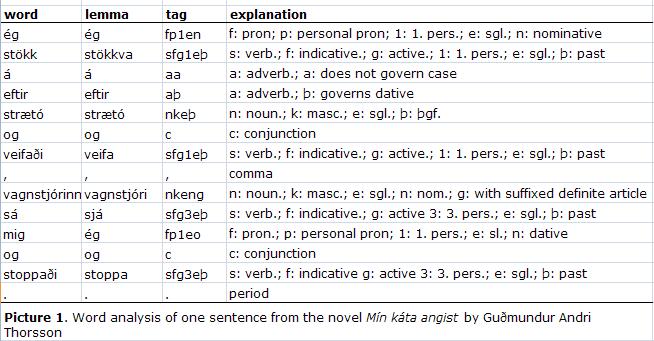
Each running word was then placed in a separate line. The morphosyntactic tags and the lemma were placed in the same line. The picture below shows one sentence from the novel "Mín káta angist" by Guðmundur Andri Thorson, and how it is analyzed. For greater clarity, an explanation is given of the morphosyntactic tag.
The preface to the IFD presents the automatic analysis that was employed in the making of the book (Pind, Magnússon and Briem, 1991). The automatic analysis is based on an analysis of 54,000 running words that had been analyzed manually in a pilot project (Magnússon, 1988). Stefán Briem (1990) outlines the methods applied in the automatic analysis. The authors of the IFD believe that about 80% of the running words were correctly analyzed in the automatic analysis. A few years later the program was refined based on an analysis of the whole text, yielding almost 90% accuracy (Briem p.c.).
The analysis of the running words used in IFD distinguishes between eight-word classes: nouns, adjectives, pronouns, independent articles, numerals, verbs, adverbs and conjunctions. Words that are not classified into these word classes were either considered foreign words or left unanalyzed. The main deviation from the standard word form analysis involved prepositions being classed as adverbs; there are therefore adverbs that govern the case. Exclamations were also classed as adverbs but the infinitive particle was classed as conjunction.
The preface of the book contains a table that describes the morphosyntactic tags that were used in the making of the book. Each grammatical feature is represented with a letter. In the table, the abbreviations are explained and are in the order that they appear in frequency tables in the printed version. In the electronic version, however, the order of the letters in the morphosyntactic tags is as in the files that were used in the compilation of the frequency tables in the book. Only lower case letters are used for the grammatical features and the order is different from that presented in the frequency tables. In the electronic texts of the IFD corpus, there are 639 morphosyntactic tags, including punctuation. There are around 700 possible morphosyntactic tags in the tagset that accompanies the digital files.
All the texts used in the making of IFD are protected by copyright. The material is made available in three different ways. Firstly, it can be searched. However, only 500 letters can be seen at a time (5-6 lines) which falls within the limits of copyright law (No. 73/1972). Second, users can obtain a copy of tagged texts to be used for grammatical research and LT projects by accepting a proprietary user licence. Third, the texts are made available for the training of statistical taggers, but then they have been broken up and arranged so that they can't be identified. See more details in Using the IFD.
While the tags in the texts of the IFD have been manually corrected, it is inevitable that some errors still remain. Hrafn Loftsson made an attempt to automatically find and correct errors in the tags of the IFD (Loftsson, 2009). The texts available through this website are corrected as described in that paper. This applies to texts that can be searched, XML files for download, and files for the training of statistical taggers.
Experiments have been made to reduce the tagset of the text of the Icelandic Frequency Dictionary (Hrafn Loftsson et al., 2011). Access is given to texts with one type of reduction which involves proper nouns where type information has been removed (names of persons, place names and other names, are all tagged as “other names” and get the tag n----s). Additionally, only one tag (ta) is used for numerical constants, i.e. these numerals are not tagged as cardinal numbers that can be declined. Users can thus download two types of data packages with texts in XML format and two types of pairs for training and testing taggers.
The texts of the IFD are available for use in three different ways:
1. Search. The search is available through the corpus page of the Árni Magnússon Institute. Grammatical information can be used to refine the search. Bibliographic information is displayed for the texts that appear in the search results.
2. Download. The texts are available in a special XML format that is defined by TEI (Text Encoding Initiative). Bibliographical information is included with all the texts. Prospective users must register and accept the terms and conditions of a proprietary user license.
3. Train statistical taggers. In order to train and test a particular tagging method, a method is often used that is based on having ten pairs of training and test sets. In each computer file of the IFD, there is a text of 5000 words from one source. The pairs were created in such a way that each file was divided into ten roughly equal parts. Each of these ten parts forms one test set and a corresponding training set contains the other nine parts. The set with the larger file is used as a training set and the smaller as a testing set. The testing sets do, therefore, not overlap but the training sets have about 80% in common. The tagger is trained and tested on all ten pairs and average accuracy is calculated. This is called a ten-fold cross-validation. Prospective users must register and accept the terms and conditions of a proprietary user license.
e-mail: clarin@clarin.is